Meta开源大模型Llama2部署指南
Meta开源大模型Llama2部署指南
# 写在前面

MetaAI在7月19日宣布开源了他们的Llama2大模型,这一消息引起了广泛关注。MetaAI的首席科学家和图灵奖获得者Yann LeCun在推特上表示,这一举动有可能会改变大模型行业的竞争格局。
这个消息的发布让人们猛然意识到,大模型格局再次发生了巨变。
开源Llama2大模型的意义重大。首先,这将为更多的研究人员和开发者提供机会去探索和利用这个强大的工具。其次,开源Llama2有助于促进知识共享和合作,推动整个行业的快速发展。
此外,MetaAI通过开源Llama2也表明他们愿意与社区合作,共同推动人工智能领域的进步。
随着Llama2大模型的开源,预计会有更多创新应用被推出,Llama2具备强大的自然语言处理能力,在机器翻译、文本生成、问答系统等领域都有广泛应用潜力。而且由于其可扩展性和灵活性,Llama2可以轻松适应不同场景和需求。
虽然Llama2开源对行业发展具有积极的影响,但也面临一些挑战。首先,如何保证开源模型的安全性和可靠性是一个重要问题。其次,大模型的训练和使用需要庞大的计算资源,这对于一些小型企业和个人开发者来说可能是一个难以跨越的门槛。
# Llama2是什么?
Llama官网的说明称Llama2是下一代开源大语言模型,可供学术研究或商业用途免费使用。
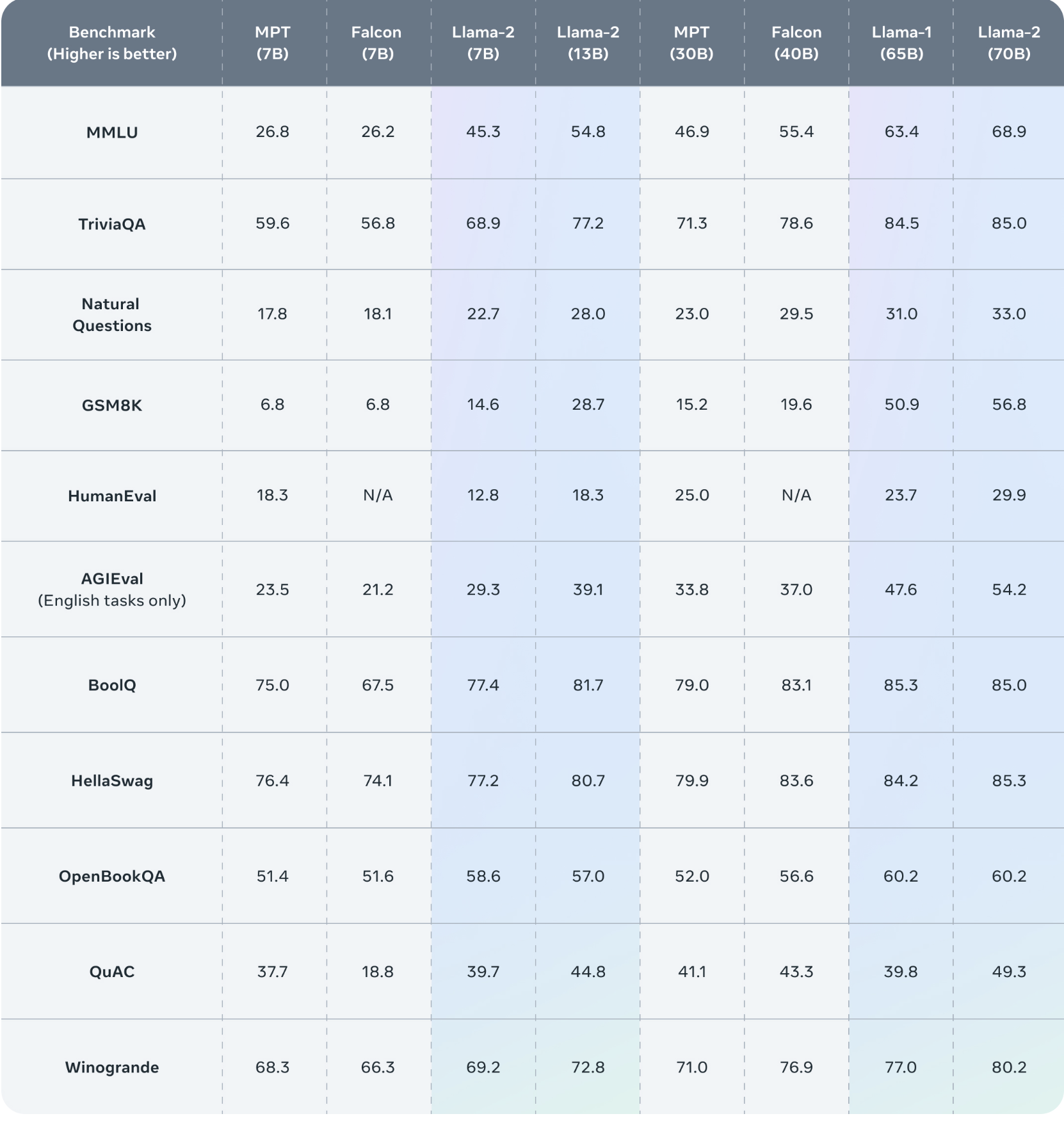
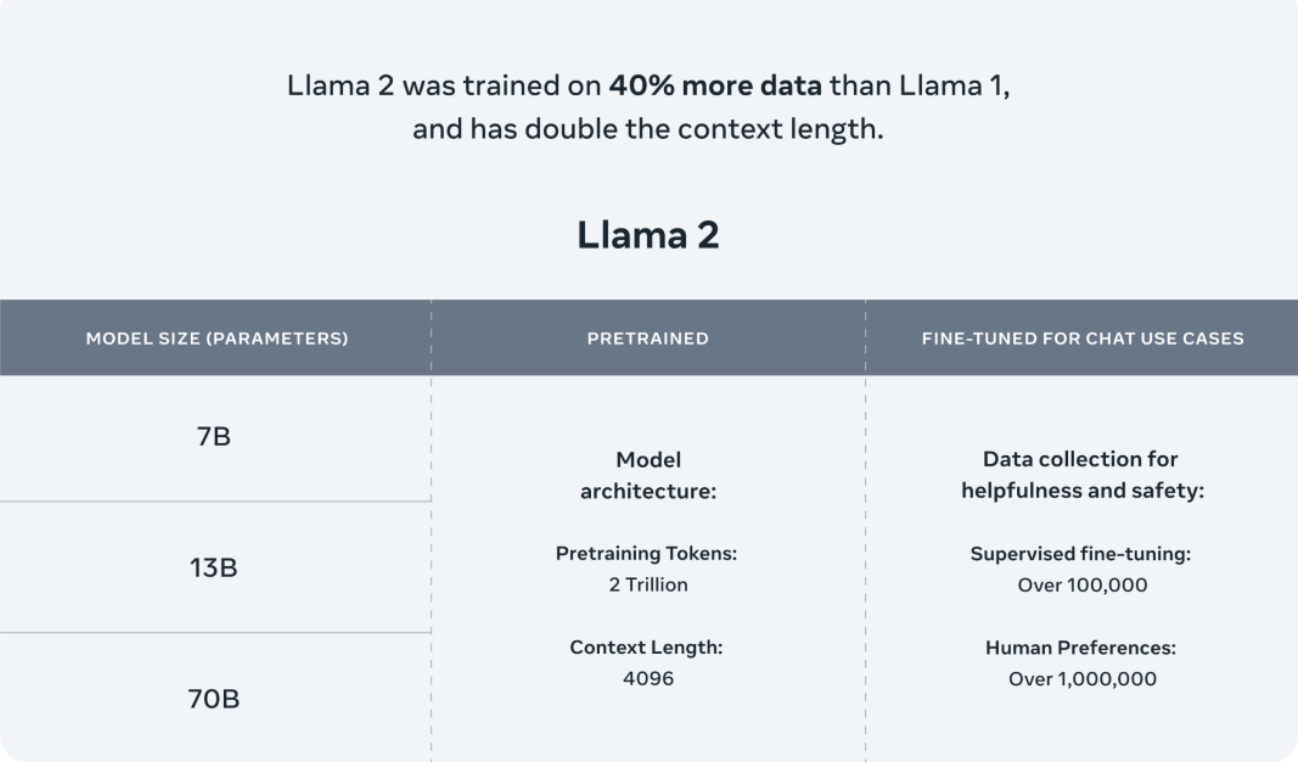
目前,Llama2提供了三种规格的模型:7B、13B和70B。在预训练阶段,该模型使用了2万亿个Token,并在SFT阶段利用了超过10万个数据和超过100万个人类偏好数据进行优化。这些丰富的数据资源为模型的性能提供了强大支持。
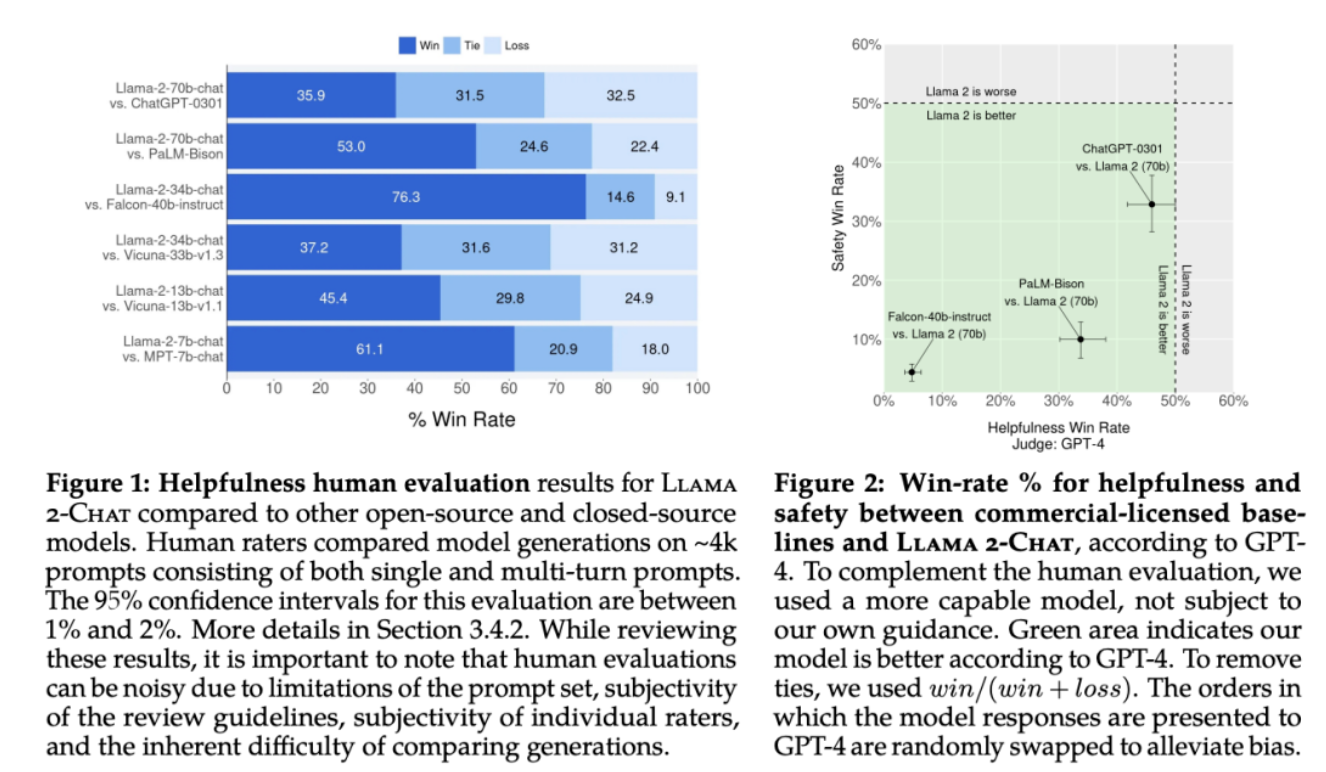
另外大家最关心的Llama2和ChatGPT模型的效果对比,在论文里也有提到,对比GPT-4,Llama2评估结果更优,绿色部分表示Llama2优于GPT4的比例
虽然中文在Llama2中的占比只有0.13%,但预计在未来会有更多中文扩充词表预训练和领域数据微调的模型被推出,以满足国内用户的需求。尽管Llama2刚刚开源几天,但已经可以在GitHub上找到基于Llama2的中文大模型项目。这显示出对于Llama2的迅速应用和广泛关注,也验证了其在中文自然语言处理领域的潜力。随着更多开发者和研究人员的参与,我们可以期待看到更多基于Llama2的创新应用和技术突破。
# 模型部署
# 国内Llama2最新下载地址
- Llama2-7B官网版本:https://pan.xunlei.com/s/VN_kR2fwuJdG1F3CoF33rwpIA1?pwd=z9kf
- Llama2-7B-Chat官网版本:https://pan.xunlei.com/s/VN_kQa1_HBvV-X9QVI6jV2kOA1?pwd=xmra
- Llama2-13B官网版本:https://pan.xunlei.com/s/VN_izibaMDoptluWodzJw4cRA1?pwd=2qqb
- Llama2-13B-Chat官网版本:https://pan.xunlei.com/s/VN_iyyponyapjIDLXJCNfqy7A1?pwd=t3xw
- Llama2-7B Hugging Face版本:https://pan.xunlei.com/s/VN_t0dUikZqOwt-5DZWHuMvqA1?pwd=66ep
- Llama2-7B-Chat Hugging Face版本:https://pan.xunlei.com/s/VN_oaV4BpKFgKLto4KgOhBcaA1?pwd=ufir
- Llama2-13B Hugging Face版本:https://pan.xunlei.com/s/VN_yT_9G8xNOz0SDWQ7Mb_GZA1?pwd=yvgf
- Llama2-13B-Chat Hugging Face版本:https://pan.xunlei.com/s/VN_yA-9G34NGL9B79b3OQZZGA1?pwd=xqrg
# Meta下载地址
Meta在Hugging Face上提供了所有模型的下载链接:https://huggingface.co/meta-llama
# 预训练模型
Llama2预训练模型包含7B、13B和70B三个版本
| 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|
| Llama2-7B | meta-llama/Llama-2-7b-hf | 模型下载 (opens new window) |
| Llama2-13B | meta-llama/Llama-2-13b-hf | 模型下载 (opens new window) |
| Llama2-70B | meta-llama/Llama-2-70b-hf | 模型下载 (opens new window) |
# Chat模型
Llama2-Chat模型基于预训练模型进行了监督微调,具备更强的对话能力
| 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|
| Llama2-7B-Chat | meta-llama/Llama-2-7b-chat-hf | 模型下载 (opens new window) |
| Llama2-13B-Chat | meta-llama/Llama-2-13b-chat-hf | 模型下载 (opens new window) |
| Llama2-70B-Chat | meta-llama/Llama-2-70b-chat-hf | 模型下载 (opens new window) |
# 模型调用代码示例
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-chat-hf',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
# Gradio快速搭建问答平台
基于gradio搭建的问答界面,实现了流式的输出,将下面代码复制到控制台运行,以下代码以Llama2-7B-Chat模型为例,不同模型只需修改一下代码里的模型名称就好了
python examples/chat_gradio.py --model_name_or_path meta-llama/Llama-2-7b-chat
# 模型微调
# 微调过程
# Step1: 环境准备
根据requirements.txt (opens new window)安装对应的环境依赖。
# Step2: 数据准备
在data目录下提供了一份用于模型sft的数据样例:
每个csv文件中包含一列“text”,每一行为一个训练样例,每个训练样例按照以下格式将问题和答案组织为模型输入,您可以按照以下格式自定义训练和验证数据集:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案
例如,
<s>Human: 用一句话描述黑皮哥是谁。</s><s>Assistant: 黑皮哥是一个人工智能助手,写代码,写文案,画海报,画头像。</s>
# Step3: 微调脚本
我们提供了用于微调的脚本 finetune.sh,通过修改脚本的部分参数实现模型的微调,关于微调的具体代码见finetune_clm_lora.py
关注黑皮哥公众号,发送微调脚本,即可免费获取
# 中文微调参数
开源Llama2中文社区使用中文指令数据集对Llama2-Chat模型进行了微调,使得Llama2模型有着更强的中文对话能力。LoRA参数以及与基础模型合并的参数均已上传至Hugging Face (opens new window),目前包含7B和13B的模型。
| 模型名称 | 🤗模型加载名称 | 基础模型版本 | 下载地址 | 介绍 |
|---|---|---|---|---|
| Llama2-Chinese-7b-Chat-LoRA | FlagAlpha/Llama2-Chinese-7b-Chat-LoRA | meta-llama/Llama-2-7b-chat-hf | 模型下载 (opens new window) | 中文指令微调的LoRA参数 |
| Llama2-Chinese-7b-Chat | FlagAlpha/Llama2-Chinese-7b-Chat | meta-llama/Llama-2-7b-chat-hf | 模型下载 (opens new window) | 中文指令微调的LoRA参数与基础模型参数合并版本 |
| Llama2-Chinese-13b-Chat-LoRA | FlagAlpha/Llama2-Chinese-13b-Chat-LoRA | meta-llama/Llama-2-13b-chat-hf | 模型下载 (opens new window) | 中文指令微调的LoRA参数 |
| Llama2-Chinese-13b-Chat | FlagAlpha/Llama2-Chinese-13b-Chat | meta-llama/Llama-2-13b-chat-hf | 模型下载 (opens new window) | 中文指令微调的LoRA参数与基础模型参数合并版本 |
# Llama2中文社区模型评测
为了能够更加清晰地了解Llama2模型的中文问答能力,我们筛选了一些具有代表性的中文问题,对Llama2模型进行提问。我们测试的模型包含Meta公开的Llama2-7B-Chat和Llama2-13B-Chat两个版本,没有做任何微调和训练。测试问题筛选自AtomBulb (opens new window),共95个测试问题,包含:通用知识、语言理解、创作能力、逻辑推理、代码编程、工作技能、使用工具、人格特征八个大的类别。
测试中使用的Prompt如下,例如对于问题“列出5种可以改善睡眠质量的方法”:
[INST]
<<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. The answer always been translate into Chinese language.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
The answer always been translate into Chinese language.
<</SYS>>
列出5种可以改善睡眠质量的方法
[/INST]
通过测试发现,Meta原始的Llama2 Chat模型对于中文问答的对齐效果一般,大部分情况下都不能给出中文回答,或者是中英文混杂的形式。因此,基于中文数据对Llama2模型进行训练和微调十分必要,目前Llama2中文社区中文版Llama2模型也已经在训练中,近期将对社区开放。
# 社区评测结果